効果的なSEOのための構造化データ利用

構造化データとは、書かれた文字が何なのかを検索ロボットが理解できるようタグ付けしたものです。
例えば、「私は山田太郎です。」という文章があった場合、人が見れば「山田太郎さんという名前の人なんだ」という事がわかります。
しかし検索ロボットにとってはただ文字が並んでいるだけに過ぎません。検索エンジンは文字の持つ意味を理解している訳ではないからです。
「私は山田太郎です。」も「ああああああああ」も、単なる同じ文字列として扱われているわけです。
これを例えば「山田太郎=これは名前を指します」と指示してあげる事によって、検索ロボットが情報の持つ意味を正しく受け取れるようになります。この仕組みで書かれたコードを、構造化データと呼んでいます。
検索エンジンとしてはそのコンテンツが何について書かれたものなのかを明確に理解できるため、当然本質的にSEO対策として有効なものになります。
また、この構造化データはWebma!テーマの中にデフォルトで組み込まれているので、お客様側での特別な設定は必要ございません。
構造化データの例
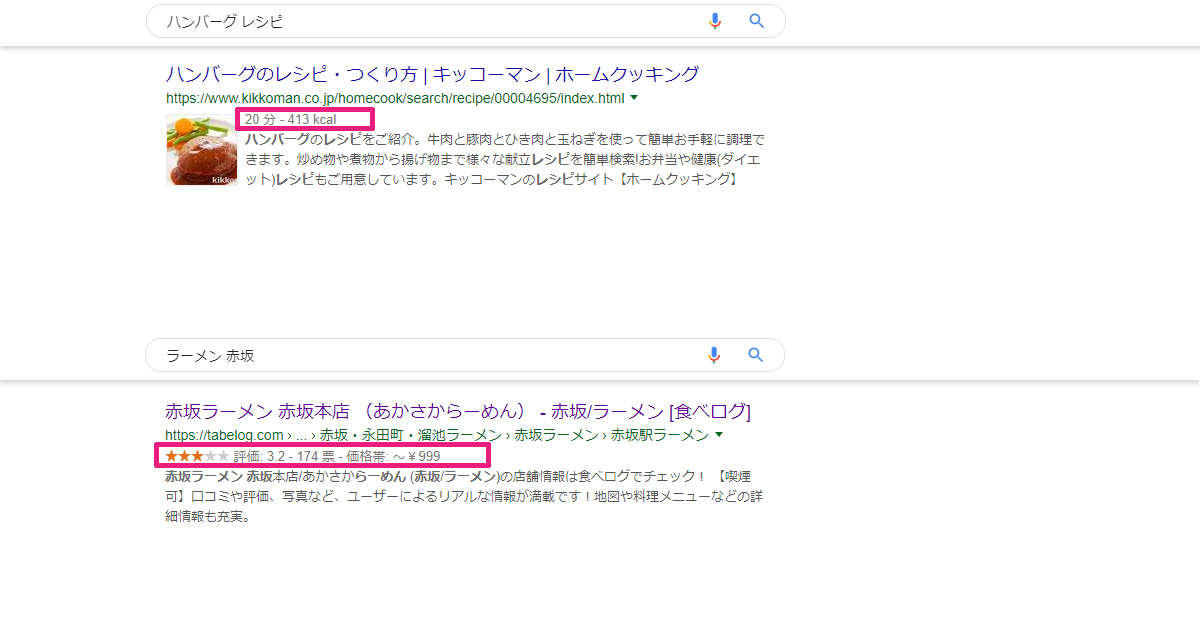
これは、レシピ検索結果と飲食店の検索結果です。
ハンバーグのレシピは、20分、413kcalと表示されています。
この情報がピックアップされていますが、これは構造化データによってGoogleが明確に作る時間とカロリーが取得できているからです。
実際にこのページのソースを見てみると、
|
1 2 |
<dd itemprop="cookTime" content="PT20M"><b title="PT20M">20分</b></dd> <dd itemprop="calories">413kcal</dd> |
といった書き方がなされています。
itemprop=“cookTime”とか、itemprop=”calories”といった文字が見えますね。
このようにタグ付けすることで、調理時間やカロリーの値を検索エンジンが理解できるようにしています。

